Cihan Ünlü
Interpreter, Academic, Researcher, Tech. Enthusiast

[Turkish] Küçük LLM’lerin Çeviri Performansı

Ticari nöral makine çevirisi (NMT) motorları Türkiye’de yüksek hacimli işlerde faaliyet gösteren işletmeler ve serbest çevirmenler için ekonomik açıdan sürdürülebilir olmayabiliyor. Bu noktada, açık kaynak büyük dil modelleri (LLM’ler) çeviri işletmeleri için potansiyel bir alternatif kapı aralayabilir mi? Bu küçük yazımda çoklu görev odaklı küçük ölçekli büyük dil modellerinin çokdilli çeviri performansını güncel akademik araştırmalar üzerinden özetlemeye çalışacağım.
Büyük dil modelleri doğal dil işlemenin pek çok alt alanında olağanüstü performans sergilemesinin yanı sıra, makine çevirisi (MT) araştırmalarında yeni bir paradigma oluşturdu. Llama, Gemma, Mixtral, Qwen gibi açık kaynaklı (open-source) ve/ya açık ağırlıklı (open-weight) LLM’ler her ne kadar veri gizliliği, maliyet açısından profesyonellere göz kırpsa da üretime alınmasında boyutları önemli bir engel teşkil ediyor. Örneğin, çoklu görevler için eğitilmiş Llama 8B modeli, açık kaynak NMT modeli NLLB-200’ün 3.3B boyutundaki modelinin iki katından fazla bir büyüklüğe sahipken, Llama 70B ve Llama 405B sırasıyla 20 ve 122 kat daha büyük. Bu devasa boyutlar, yüksek hesaplama kaynakları ve altyapı gerektirdiğinden, üretim ortamında ekonomik ve pratik açıdan uygulanabilirlik sorunlarına yol açabiliyor.
Yerel olarak ayağı kaldırılan modeller artık herkes için kullanılması ve erişilebilmesi daha kolay hale gelmişken, düşük maliyetlerle bir sunucuda çalıştırabileceğimiz Minik LLM’ler etkileyici sonuçlar elde edebiliyor. İlk bakışta bu modelleri çeviri görevleri için de kullanabileceğimiz fikri akla gelse de durum sandığımızdan daha karışık.
Temel sorunlardan biri çok bariz: bizi hayrete düşüren modellerin çoğu; İngilizce, Çince, Fransızca, İspanyolca üzerine odaklanmış durumda; bu da düşük kaynaklı dillerin çeviride yetersiz kalmasına yol açıyor. Araştırmalar da benzer şekilde dengesiz eğitim verisi dağılımının temel zorluklardan biri olduğunu ortaya koyuyor. Çözüm basit ama bizi bir takım zaman harcayan deneme-yanılma çalışmalarına sürüklüyor. Continual pre-training (Xu et al., 2024), supervised fine-tuning (SFT) (Li et al., 2023; Moslem et al., 2023; Wu et al., 2023) ve contrastive learning (Li et al., 2024) gibi yöntemlerle çok dilli performansı artırmaya yönelik bazı çabalar var.
Çeviri görevi odaklı çıkarsama (inference) üzerine yapılan araştırmalarda birkaç temel eğilim göze çarpıyor. Birincisi, LLM’lerin in-context (bağlam içi) çeviri yeteneklerini keşfetmek. Bazı çalışmalar anlamsal olarak ilişkili paralel cümlelerin prompt içinde örnek olarak kullanılmasıyla MT performansının artırılabileceğini gösteriyor (Moslem et al., 2023) . Modelin daha önceki çeviri örneklerinden öğrenerek çevrim içi adaptasyonu, “chain-of-thought prompting” yöntemleriyle çeviri “insan benzeri” düşünce zincirleri eklenmesi ve temel model (base model) ön eğitiminin (pretraining) geniş veri kütüphaneleriyle desteklenmesinin çeviri başarısına büyük katkı sağladığı vurgulanıyor (He et al.,2024). Yetersiz kaynak ve yetersiz paralel veri bulunan senaryolarda umut verici bir yöntem. Öte yandan, LLM’lerin bu in-context öğrenme özelliğinin temel avantajlarından biri, tüm belge veya proje genelinde tutarlılık, alan terminolojisi ve biçemin kontrol edilebilmesi.
Araştırma kolunun diğer kısmında küçük paralel veri setleriyle yapılan ince ayar yöntemi (fine-tuning) öne çıkıyor. Bazı çalışmalar, anlamsal olarak ilişkili paralel cümle örneklerinin eğitim verisi olarak kullanılmasıyla MT performansının artırılabileceğini gösterirken, diğer yaklaşımlar paralel verinin sürekli ön eğitim sürecindeki etkisini araştırıyor (Guo et. al, 2024). Bu rekabetin çıktılarını, modelleri çeşitli yöntemlerle birbirleriyle kıyaslayan çalışmalardan görüyoruz. Zira genel yaklaşım bu dil modellerinin Sadece belirli dil çiftlerine odaklansalar da, günümüzdeki durumu görece ortaya koyan ve gelecek hakkında tahmin yapmamızı sağlayan bazı bulgular mevcut. Yazıyı uzun tutmamak için sadece birkaç önemli çalışmadan bahsedeceğim.
Wassie et al. (2024)’e göre 8B parametreli decoder‑only LLM’ler (örneğin, Mistral 7B, Llama‑3 8B) medikal çeviride (Portekizce-Swahili-Fransızca) zero-shot çeviri performansının, encoder‑decoder mimarisi kullanan ve görev odaklı fine‑tune edilmiş NLLB‑200 3.3B modeline göre geride kalıyor.
Bu araştırmaların şaşırtıcı bir son örneği Xiaomi’den geldi. 7 Şubat’ta yayınlanan makalede (Cui et al, 2025) çeşitli benchmarking veri setleri Mistral-7B-v0.3, Qwen2/2.5–7B, LLaMA3/3.1–8B ve Gemma2–9B gibi popüler modellerde farklı dil çiftleri üzerinde test edildi. Araştırmacılara göre Gemma2–9B, diğer açık kaynaklı modellerle karşılaştırıldığında dil çeşitliliği açısından üstün tokenizasyon verimliliğine sahip. Dolayısıyla Gemma2–9B gibi modellerin çok dilli çeviri alanında etkileyici performans sergilediğini fark eden araştırmacılar modelin dil çeşitliliği ve genel çeviri başarısını artırmak amacıyla, sürekli ön eğitim (continual pre-training) aşamasında tek dilli (monolingual) ve paralel verilerin optimal karışımını sağlayan Parallel-First Monolingual-Second (PFMS) veri karışım stratejisini kullandı. Gemma2–9B modelinin daha da geliştirilmesiyle, GemmaX2–28–9B adlı, 28 dili kapsayan ve Google Translate ile GPT‑4‑turbo ile rekabet edebilecek seviyede çeviri kalitesi sunan bir model ortaya koymuş oldular. Yeni model GemmaX2–28–9B HuggingFace’de herkese açık bir şekilde yayınlandı.

Öne sürdüklerine göre bu model ticari sistemlerle (Google Translate, GPT‑4‑turbo) rekabet edebilecek seviyeye ulaşmış. Bu araştırmayı ilginç kılan şey testlerin belirli bir dil çiftine değil de Türkçeyi de içeren 28 dil çifti için yapılmış olması. XCOMET / COMETKiwi ve spBLEU / COMET skorları Türkçe’nin de GPT-4Turbo ve Google Translate seviyesinde performans gösterdiğini iddia ediyor. Modelin kuantize edilmiş versiyonları mevcut. Yakında Türkçe için deneyip deneyimlerimi paylaşacağım.
Genel olarak yapılan araştırmalar ışığında baktığımızda özellikle belirli bir alan için çeviri yapıldığında (domain-specific), geleneksel encoder-decoder MT modellerinin hala geçerli ve başarılı olduklarını bir kere daha görüyoruz. Gelecek ne getirir bilinmez ama görev odaklı (MT-task-specific) encoder-decoder MT modelleri, yüksek kaliteli domain-specific çeviri iş akışlarında hala temel bir bileşen. Günümüzde LLM’ler hala farklı diller ve alanlar arasında tutarsız kalitede sonuçlar üretebiliyor. Devasa boyuttaki modeller ( Llama-3.1 405B, DeepSeek-v3 685B) her ne kadar yeterli performans gösterseler de çoklu üretimde etkin kullanılabilmesi günlük kullanıcılar ve KOBİ’ler için pek mümkün görünmüyor.
Açık kaynak perspektifinden Türkçe NMT performansının durumuna baktığımızda hala ince-ayar yapılmış NLLB-200 ve OpenNMT modelleri diğer oyunculara göre daha iyi performans vereceği aşikar.
Türkçe için henüz LLM tabanlı çeviri görevleri için detaylı bir benchmarkingçalışması mevcut değil. Baştan pre-training maliyetli ve sürdürülebilir olmasa da, tokenizasyon verimliliğinin en yüksek olduğu modeller seçilerek Türkçe gibi kimlerine göre “düşük” kimlerine göre “orta” ölçekli veri kaynağına sahip bir dil için yukarıda bahsettiğim PFMS gibi yöntemlerle uzmanlık alanları için eğitilebilir. LLM’lerin bulanık eşleşmelerle (fuzzy match) few-shot promptlanması, RAG gibi yöntemlerle TM gibi dış verilerle beslenen bir “post-editing düşünce zinciri“ prompt’u (doküman düzeyinde olmasa da cümle düzeyinde) EN-TR için rekabetçi bir sonuç verebilir. Doğru mali çözüm ve doğru modelle çeşitli uzmanlık alanlarında metinleri doküman düzeyinde NMT çıktılarını kontrol eden akıllı bir son-okuyucu olabilir.
LMStudio, AnythingLLM ve Groq gibi platform/yazılımlarla sıradan günlük kullanıcıların radarına giren ve belirli bir GPU gücüne sahip bilgisayarlarda verimli sonuçlar veren LLM’ler bir gün serbest çevirmenlerin de bilgisayarına girebilir. Şu anda en az 24 GB RAM’e sahip Apple Mac Mini M4 Pro veya en az 12 GB VRAM’e sahip Nvidia RTX 3060’li bir masaüstü bilgisayar bu modelleri saniyede az 20 token üretecek kadar çalıştırabiliyor. Elbette bu modellerin nasıl ve neden çevirmenin iş akışına gireceği RWS, Translated, MemoQ, Phrase gibi çeviri teknolojileri devlerinin yeni uğraşı. Zaten belli bir ölçüde otomasyondan nasibini almış çeviri iş akışının büyük dil modeli tabanlı çözümlerden ne derecede faydalanacağını hep birlikte göreceğiz.
Deepseek vb. modellerinin yarattığı yeni “açık ağırlık, açık kaynak” dalgasının etkisiyle birlikte belirli grup veya şirketlerin tekelinde olmayan yapay zeka modelleri gelecekte giderek yaygınlaşacak. Daha az maliyet gerektiği durumlarda bu modeller herkesin yararına olacak bir düzlemde meyvelerini verecek. Ancak o zaman LLMler, çevirmenler ve çeviri işletmeleri için dışa bağımlılığı azaltan, veri gizliliği konusunda endişe yaratmayan bir alternatif haline gelebilir.
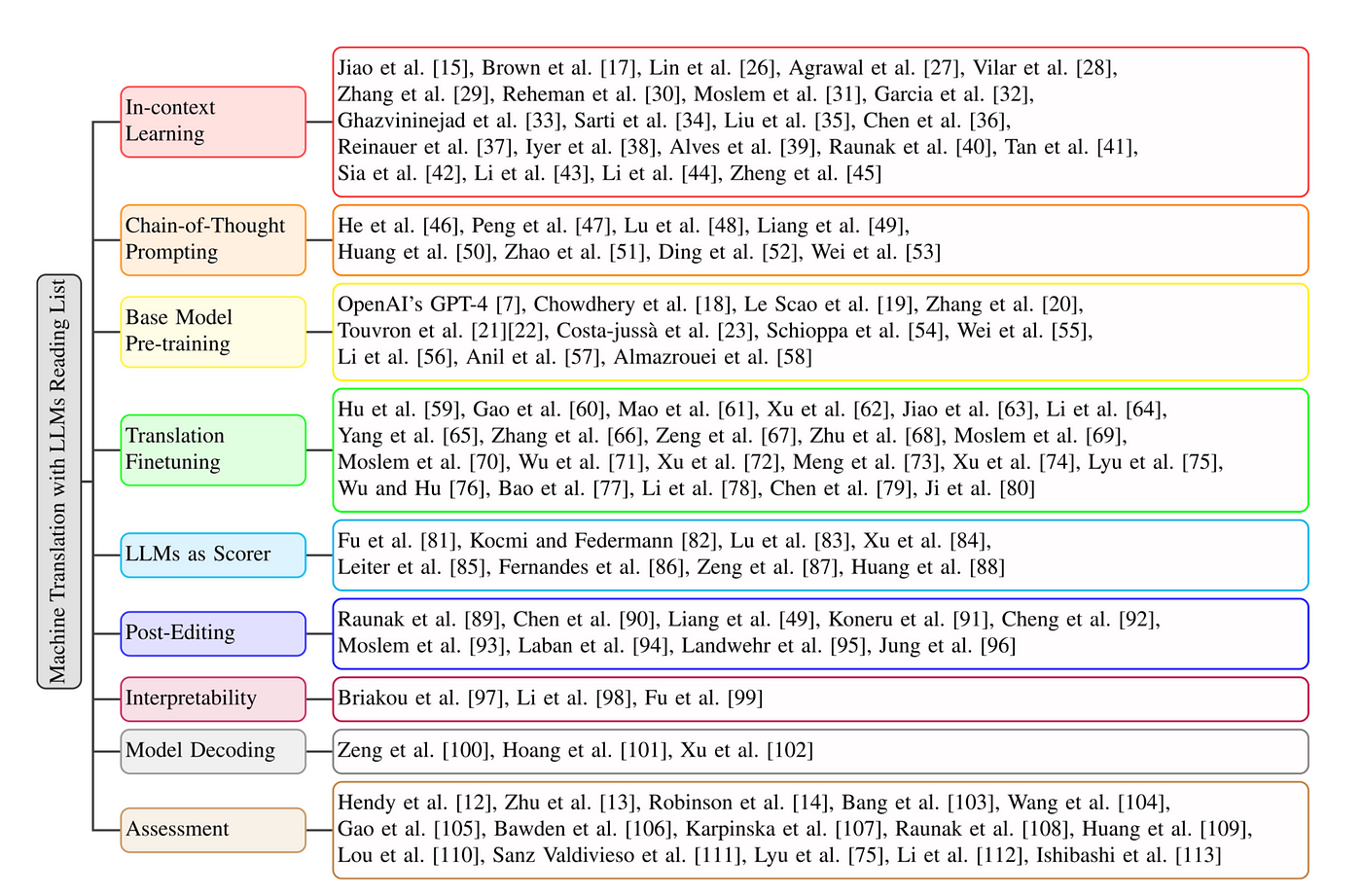
Son olarak, Wang et. al (2024) tarafından “Recent Advances in Interactive Machine Translation With Large Language Models” başlıklı makalesinde yayınlanan bir okuma listesi tablosu görselini paylaşıyorum. LLM’lerle MT çalışmaları yürüten hem sosyal bilimler hem de mühendislik araştırmacıları için değerli bir kaynak. 👇